LETUS: A Log-Structured Efficient Trusted Universal Blockchain Storage
Blockchain Background and Challenges
What Is Blockchain Storage and What Are Its Challenges
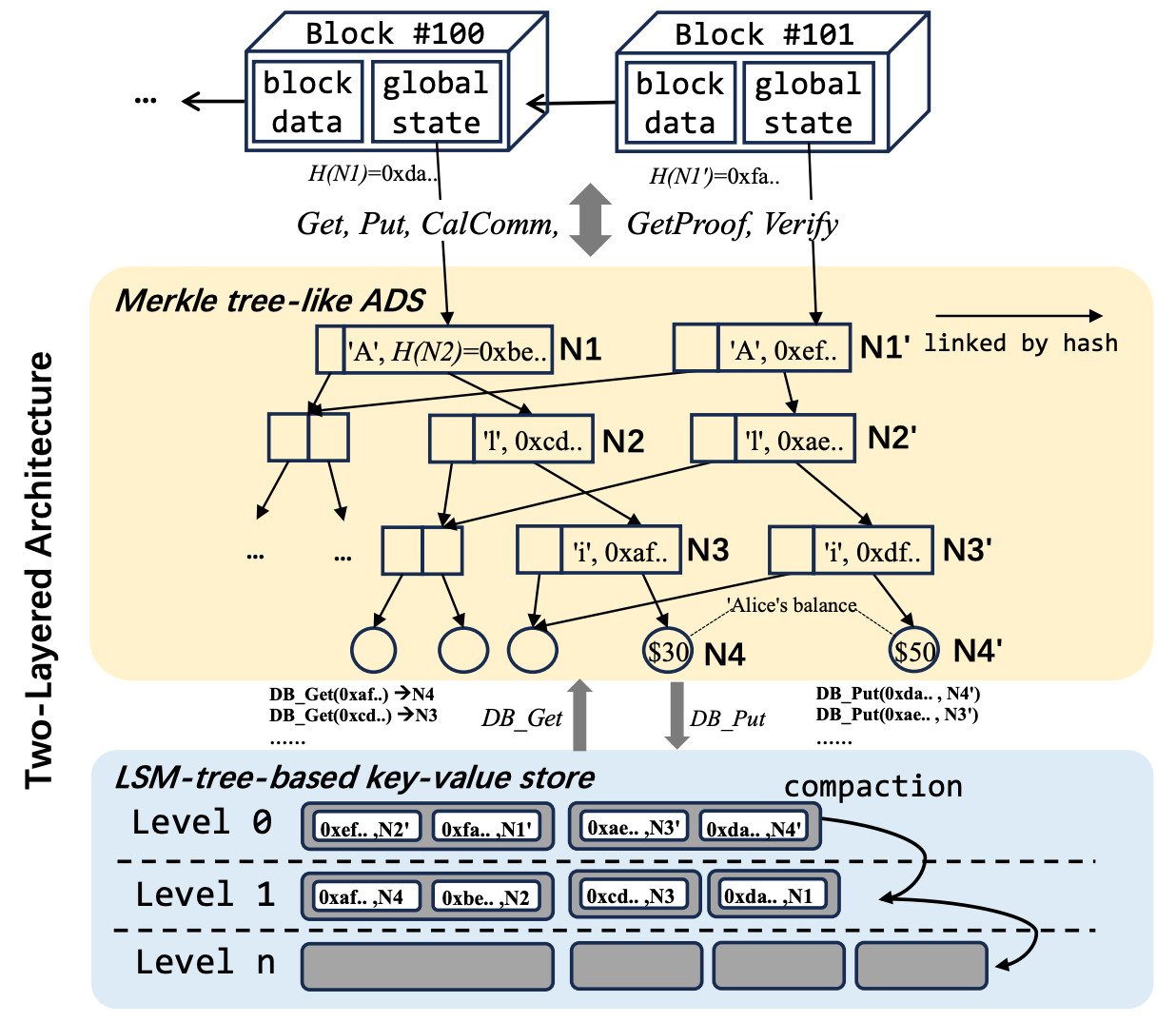
Blockchain data is composed of block data and global state. Block data includes an ordered list of transactions (TXNs), digests, and so on. Global state includes the state of accounts and contracts, such as balances. Global state is frequently accessed during TXN execution.
Different from traditional database, blockchain storage is authenticated and multi-versioned. That is, the global state must be cryptographically verifiable, and all historical data could be tracked and audited. Blockchain storages build Authenticated Data Structure (ADS) to realize the authentication, so anyone is able to verify the correctness of the data.
There are two major challenges in blockchain storage:
- Poor storage performance: Recent studies have discovered I/O bottleneck in blockchains. Storage consumes a significant proportion (i.e., 81%) of the overall tansaction processing time[1], and it becomes more expensive as blockchain data volume grows[2].
- Increasing resource consumption: The data volume of an Ethereum archive node has already surpassed 15 TB since Nov 2023, with an annual growth rate of 1.5-2.0×. In AntChain enterprise scenarios, it is increasing at an even higher speed. With the growth of data volume, resource consumption, including space usage and bandwidth consumption, increases rapidly.
The challenges arise from the distinctive requirements of blockchain storage. Different from traditional databases (i.e., key-value stores or SQL databases), blockchain storages are authenticated and multi-versioned. They typically implement a two-layered architecture, which consists of a LSM-tree-based key-value store as storage backend, such as LevelDB and RocksDB, and an ADS on top. These ADS are typically implemented using cryptographic hashing and Merkle tree, such as Merkle Patricia Trie (MPT) in Ethereum.
An Example of Typical Storage
We could take a simple payment example to illustrate how it works. In the figure, a TXN is submitted in block #101 where Alice’s balance increases from $30 to $50. To get Alice’s origin balance, we need to read the N1~N4 using their hashes. Each node read operation involves multiple I/O operations due to the multi-level SST-files. To update Alice’s balance, all N1∼N4 are duplicated and updated as N1’~N4’ due to the Merkle hash recalculation. All new nodes are then written to key-value store using their hashes as keys, which are totally randomly distributed.
Why Do These Challenges Exist?
We could summarize 5 problems to solve for the two-layered architecture: performance, scale bottleneck, cost, I/O amplification, and data locality. The reasons come from 3 aspects:
- Long I/O path and insufficient use of cache due to the two-layered architecture. A state access request involves multiple node queries in the tree. And each node query necessitates multiple disk I/Os in the database. Only the latest versions are accessed during TXN execution,but the backend database isn’t version-aware.
- I/O amplification and space amplification caused by tree encoding. When updating a single object, all the nodes along the vertical path from leaf to root need to be persisted into backend storage.
- Heavy usage of I/O bandwidth caused by randomness of hash-based key schema. As the hash based keys are randomly distributed, SST-file at a lower level intersects with multiple files at higher levels. Then compactions will merge and rewrite levels of SST-files to maintain the orderliness.
Existing Solutions
Numerous studies have strived to optimize blockchain storage, however, none of them effectively addresses all of these issues. We have classified the existing work into three categories.
- Weaken verifiable features. Hyperledger Fabric V1.0[3] introduces a read-write-set structure to replace the Merkle tree. The read-write-set improves the performance, but does not support state verifiability, which is necessary for many applications.
- Optimize Merkle tree. DiemDB[4] employs JMT as ADS and implements a version-based indexing schema. JMT greatly reduces I/O overhead, but still has a limited performance under large-scale blockchain data volumes due to the I/O amplification caused by tree encoding. RainBlock[2] introduces a sharded, multi-versioned, in-memory Merkle tree, known as the Distributed Sharded Merkle Tree (DSM-Tree), to boost the performance. However, it persists state by checkpointing, which consumes significant space usage and increases failure recovery time.
- Explore new architecuture. ForkBase[5] aims at reducing the development efforts for applications requiring data versioning, tamper evident, and fork semantics. It break the two-layered architecture, however, it utilizes chunk-based deduplication which is not effective in blockchain because the size of updates of global state is smaller than a chunk. Furthermore, it uses unefficient hash-based indexing schema.
Our Solution: LETUS
Architecture Overview
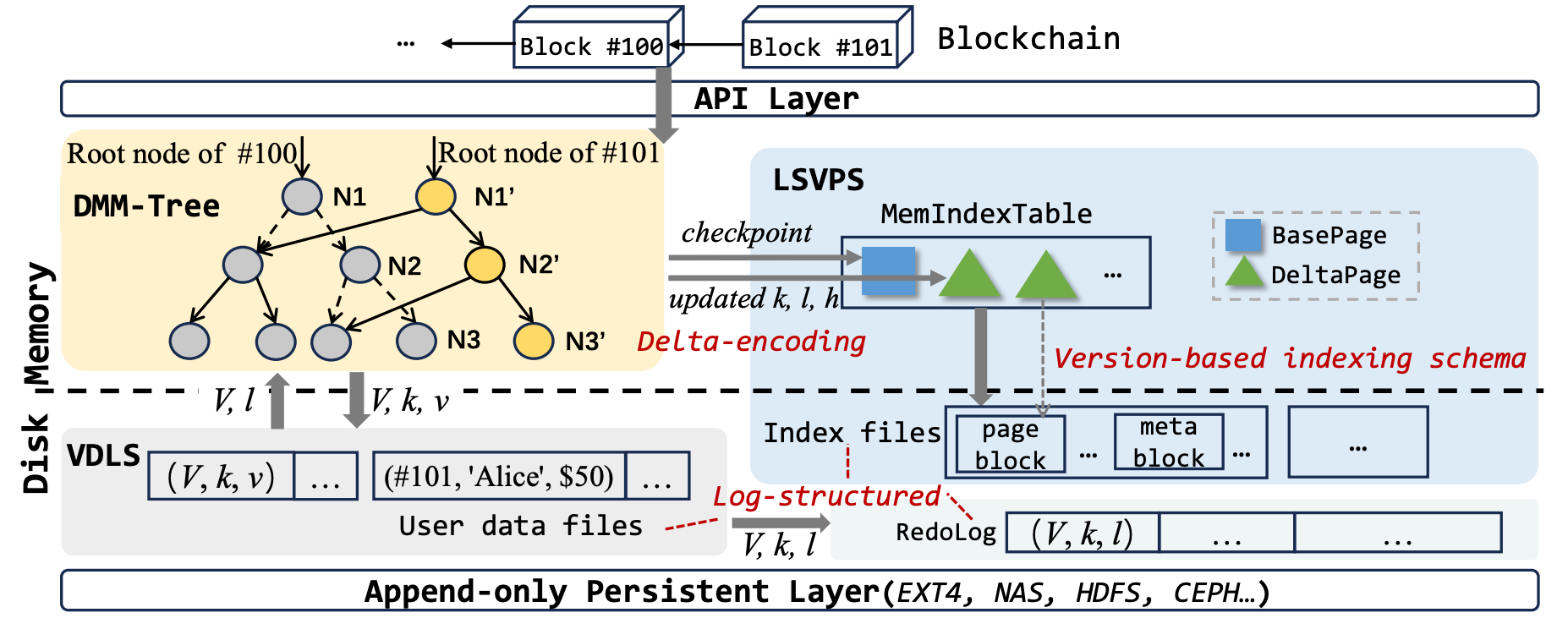
To address the aforementioned challenges, we introduce LETUS with a redesigned architecture, which provide a high performance, large scale, low cost blockchain storage solution. LETUS composes of three major components: DMM-Tree, LSVPS and VDLS.
DMM-Tree (Delta-encoded Multi-version Merkle Tree) functions as a built-in multi-version Merkle tree, provides cryptographic verification. LETUS manages DMM-Tree in page form, where a two-level subtree is aggregated into a page to aligns with the block size of typical filesystems. LETUS is a universal architecture with framework design that supports various tree structures, including B+-trees and Tries. In the current implementation of AntChain, we have adopted a trie structure denoted as DMM-Trie.
LSVPS (Log-Structured Versioned Page Store) is a log-structured, versioned, page abstraction storage subsystem used to store a large volume of pages generated by DMM-Tree. Every node in DMM-Trie is assigned a 64-bit integer 𝑉 that signifies the data version. Each page is also assigned a page version, which indicates the latest version of the data it holds. LSVPS stores pages in a log-structured fashion, wherein data is natively sorted by version. Based on this, LETUS implements a version-based indexing schema for data indexing, deviating from the traditional hash-based indexing schema.
VDLS (Versioned Data Logging Stream) is an append-only logging stream that stores all versioned user data records in the form (𝑉 , 𝑘, 𝑣), where 𝑉 denotes data version, and (𝑘, 𝑣) denotes a key-value pair. VDLS comprises a sequence of data files, each identified by a unique file ID and comprises a sequence of records. Each record is identified by a tuple of (𝑓𝑖𝑙𝑒𝐼𝐷, 𝑜𝑓𝑓𝑠𝑒𝑡, 𝑠𝑖𝑧𝑒), representing its unique location 𝑙 in the stream. The locations are stored in leaf nodes of DMM-Trie.
In addition, LETUS provides an Append-Only Persistent Layer, which is designed to offer flexible support for modern storage devices, including SSDs/NVMe or cloud storage.
Delta-Encoding and Version-Based Indexing
We propose delta-encoding and version-based indexing to address the I/O amplification and data locality, thereby significantly enhancing performance.
Delta encoding. A naive method of persisting DMM-Trie is to flush the entire page after any data update. However, this approach leads to severe write amplification and space consumption since only a small portion of the page is actually updated. To address this issue, we proposes delta-encoding.
Through delta-encoding, the incremental updates of a page are aggregated into DeltaPages and persisted instead of the full page. Specifically, after updating a key-value pair, the updated leaf node and hash of child node in the index nodes are written to the corresponding DeltaPage. To control the DeltaPage size, we set a threshold 𝑇𝑑 . When a DeltaPage accumulates 𝑇𝑑 updates, it is frozen and a new active one is initiated. To minimize overhead when reloading a page, we set a threshold 𝑇𝑏 . Each page generates a checkpoint as BasePage after every 𝑇𝑏 updates.
Version-based indexing. LETUS utilizes the ordered properties of data version in blockchain and designs a version-based indexing schema. Each node and page in DMM-Trie retains a version that records the latest version of data it contains. And each page records the versions of its children. LSVPS provides a page query interface based on 𝑉, and maintains a B-tree-like structure for efficient page indexing. Pages are natively stored in the order of 𝑉, eliminating the need for internal compactions.
In contrast to the hash-based indexing schema, the version-based indexing schema could significantly reduce disk bandwidth. Furthermore, the ordered storage of pages in the persistent layer enables easy execution of range operations on pages. For instance, historical pages older than a given version can be pruned in batch.
Example. Let’s take an example of how LETUS works. The figure uses arrows to demonstrate the write and read flows.
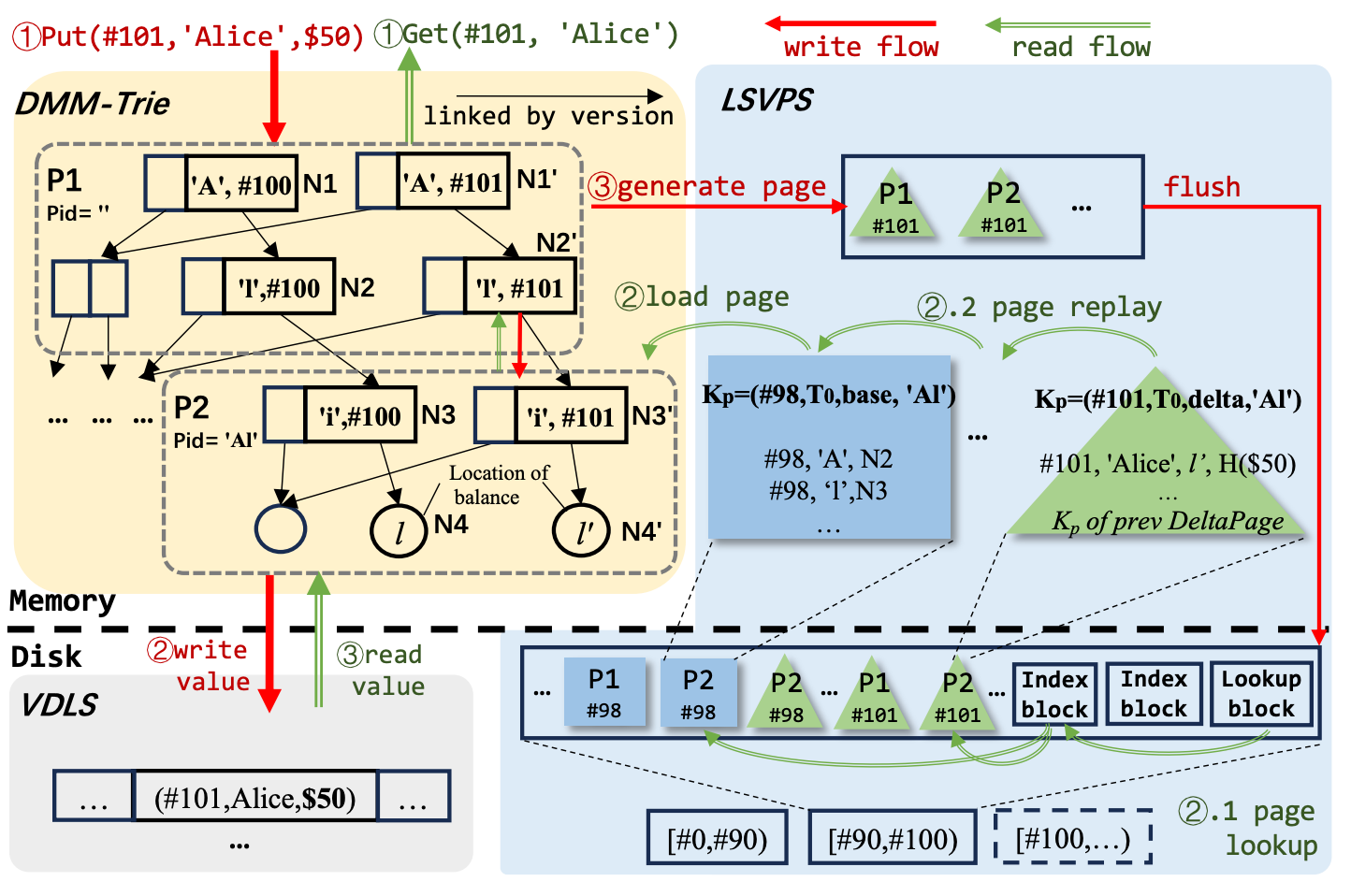
The write flow of Put(#101, 'Alice', $50) involves three phases:
① The operation first updates DMM-Trie, recursively generates and updates N1', N2' in root page P1, and N3', N4' in leaf page P2.
②The user data record is appended into VDLS and the location is subsequently recorded in N4'.
③Node updates are packed into DeltaPages. For example, the modifications in N4' ('Alice', 𝑙', H($50)) will be recorded in the DeltaPage of P2.
This DeltaPage is buffered in MemIndexTable, and flushed as an index file if reaching the size threshold.
Read Flow of Get(#101, 'Alice') also involves three phases:
①Pages P1 and P2 in DMM-Trie are recursively read if in memory cache. Otherwise, they need to be loaded from persistent layer.
② The page loading consists of two steps: page lookup and page replay. Take P2 as an example. Firstly, look up the latest BasePage that is smaller than #101 (#98 in this example). Then look up DeltaPages whose version is between #98 and #101. To speed up the load process, LETUS records the page key 𝐾𝑃 of last DeltaPage in each DeltaPage. LSVPS searches 𝐾𝑃 in lookup block to find out which index block contains the mapping of 𝐾𝑃 to its location. Next, LSVPS searches the specific index block and locates the physical page via its location. After page lookup, we replay DeltaPages in the version order to the BasePage.
③ Now it is able to read the location stored in P2's leaf node, and then obtain Alice's latest balance from the record in VDLS.
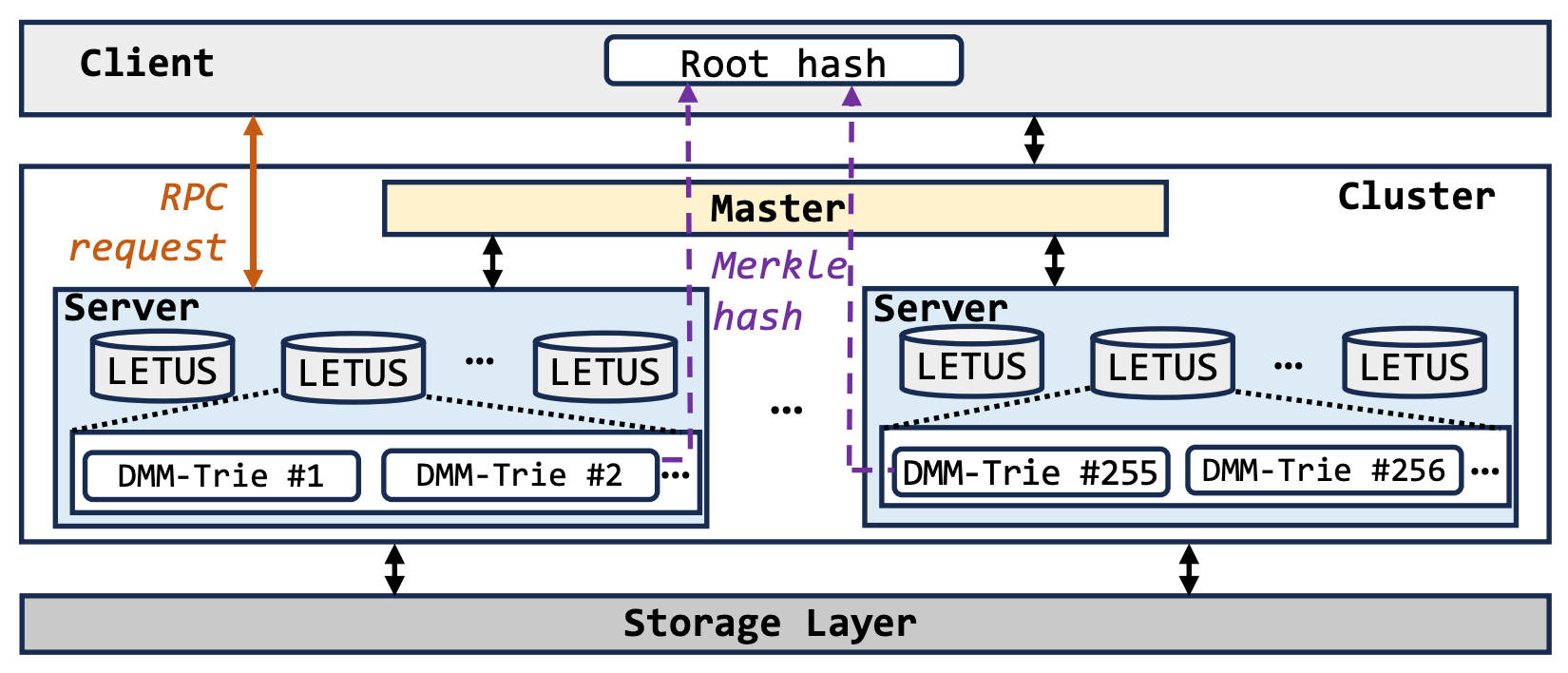
Scalability
As the application scales, the data volume could surpass the resource capacity of a single node. To address the scale bottleneck, LETUS adopts a subtree-level sharding schema, scale data and workload across a cluster. The client consistently maintains the root node and its 16 children, then the 256 vertical subtrees are distributed among servers. We implement a uniform hash routing policy and two-level placement policy to ensure load balancing.
For efficient system management, a single LETUS instance maintains multiple subtrees, and each server operates several LETUS instances concurrently. As data volumes increase, we can effortlessly scale the 256 subtrees to more servers by adjusting the number of LETUS and DMM-Trie instances on each server. Currently, for the implementation of TopNod with AntChain, 4 servers efficiently handle large data volumes, with 8 LETUS instances per server and 8 DMM-Trie instances per LETUS instance.
Tiering and Pruning
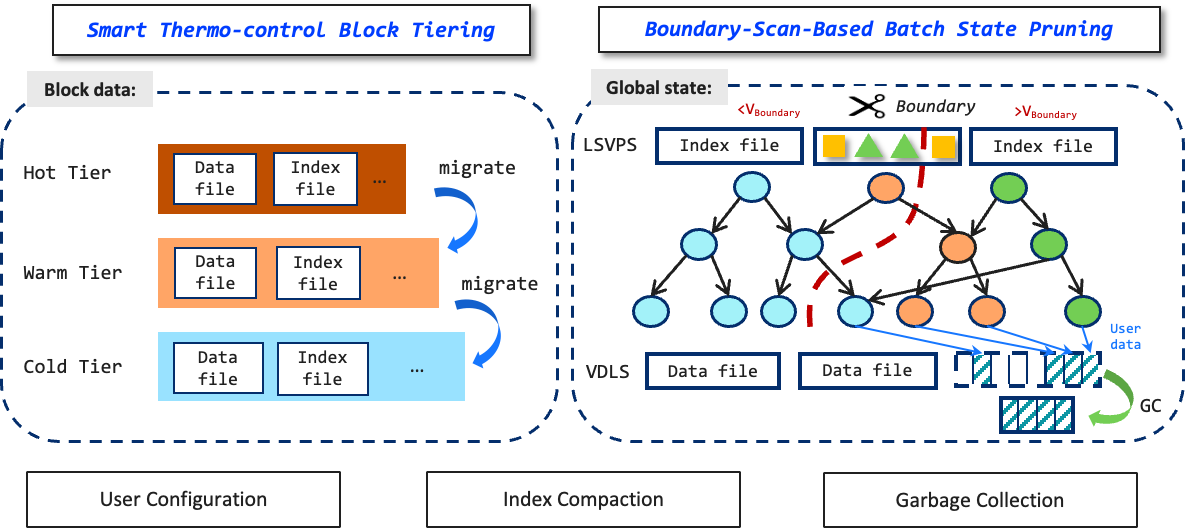
Users may prefer to minimize storage cost for less frequently accessed or unnecessary versions of data. LETUS supports block tiering and state pruning as user configurable supplementary features to reduce storage cost.
Block data exhibits a significant imbalance in access frequency. Specifically, new blocks are accessed more frequently than stale blocks. Based on this, we introduce a Smart Thermo-control Tiering algorithm to automatically migrate stale block data from high-performance but expensive devices (hot tier), to cheaper but lower-performance devices (warm and cold tiers).
State pruning allows the deletion of unnecessary data older than the given version 𝑉𝑇. We introduce a Boundary-Scan-Based Batch Pruning algorithm to enhance efficiency. The state pruning process consists page pruning in LSVPS and user data garbage collection (GC) in VDLS. During the page pruning phase, the LSVPS searches for the first BasePage with a version 𝑉𝐵 that is less than or equal to 𝑉𝑇 for each page in the DMM-Trie. 𝑉𝐵 serves as a boundary version; pages with a version less than 𝑉𝐵 contain only unnecessary data and can be safely deleted in batch. During the GC phase, user data records in VDLS that are no longer referenced by LSVPS are marked as garbage. Valid data will be rewrite into a new data file when the original data file contains too much garbage, and the original data file is recycled subsequently.
Data model and data verification
LETUS utilizes an extended multi-versioned key-value data model with Merkle proof, and exposes a set of simple and user-friendly APIs as listed in the table. Data is represented by a tuple of (𝑉, 𝑘, 𝑣). DMM-Tries is identified byTid.
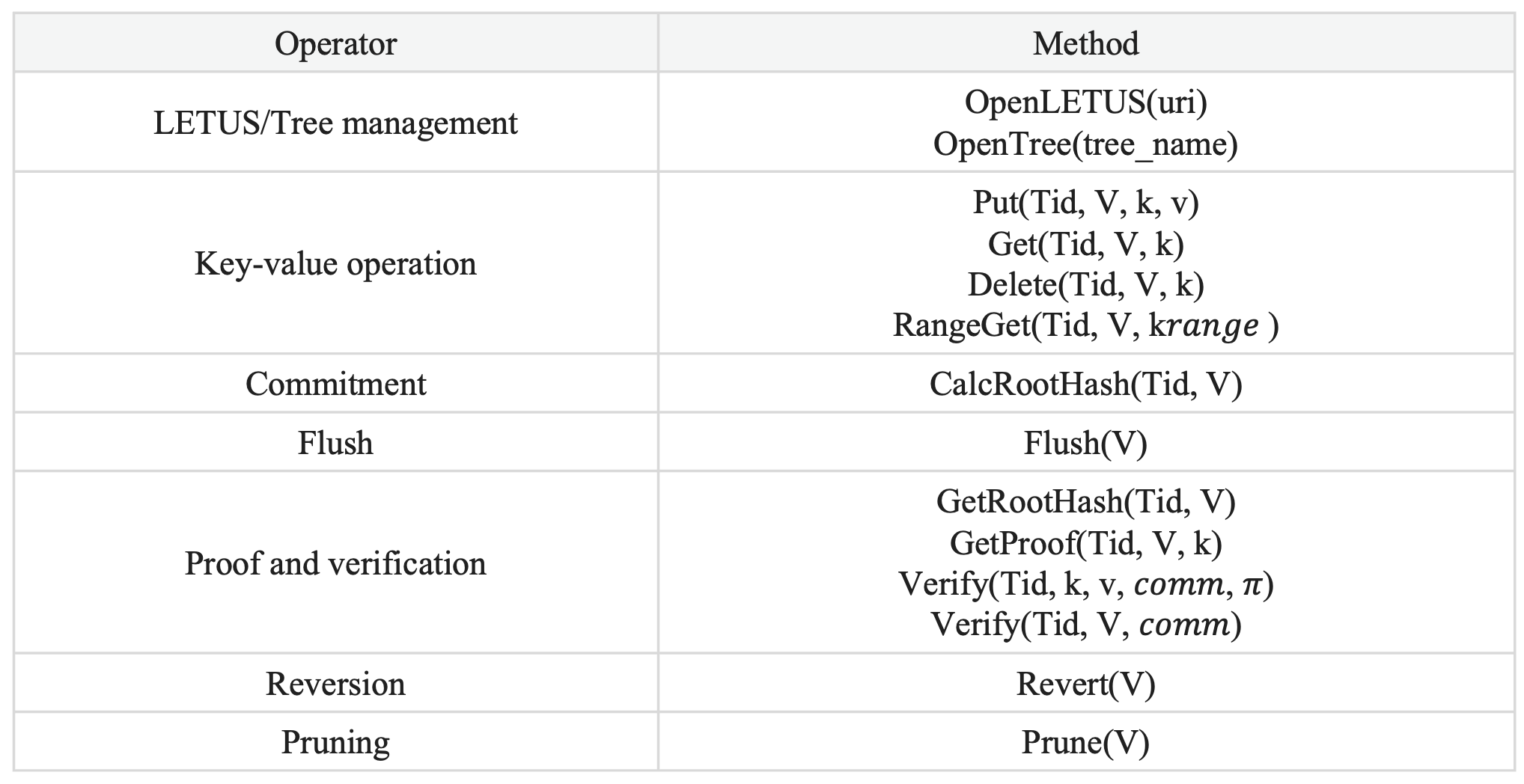
LETUS guarantees data forwardintegrity[5], tampering will be detected when data verification is executed. We denote 𝑉 as version, (𝑘, 𝑣) as a key-value pair, 𝑐𝑜𝑚𝑚 as the commitment of ADS (i.e., root hash of DMM-Trie when version 𝑉), 𝜋 as the proof. Three types of data verification are supported:
- Digest verification: Compares (𝑉, 𝑐𝑜𝑚𝑚) pairs with the external redundancy to quickly detect rollback or forking attacks.
- Proof verification: Given a (𝑉 , 𝑘) pair, LETUS provides Merkle proof 𝜋 via 𝐺𝑒𝑡𝑃𝑟𝑜𝑜𝑓 (𝑉 , 𝑘), and then verify Merkle hash from leaf to root through 𝑉𝑒𝑟𝑖𝑓𝑦(Tid,,𝑘, 𝑣, 𝑐𝑜𝑚𝑚, 𝜋).
- Full verification: 𝑉𝑒𝑟𝑖𝑓𝑦(Tid, 𝑉, 𝑐𝑜𝑚𝑚) to verify all the data in VDLS and LSVPS. All the node hashes are recalculated and compared from the leaf to the root.
Evaluations
Effects of LETUS with Different Blockchains
To show the effectiveness of LETUS, we replace the authenticated storages in four blockchains with LETUS (indicated as blockchain-lt), and evaluate the end-to-end performance and resource usage of both the original ones and those with LETUS. Four blockchains are evaluated: Ethereum (Eth), BNB Smart Chain (BSC), AntChain Blockchain Platform (ABP), ABP with Node sharding (ABN).
We generate two workloads to simulate the real-world transactions: (1) Simple payment: It is the most common transaction in blockchains where a sender simply transfers a non-zero balance to the receiver. (2) ERC-20 transfer: It is the transaction that executes the transfer function of the ERC-20 smart contract. In both workloads, 80% of accounts are called 20% of the time, while the remaining 20% of accounts are called 80% of the time.
All experiments were conducted on servers with ecs.g7.16xlarge instance from Alibaba Cloud. Each node runs CentOS Linux release 7.2.1511 and is equipped with a 64-core Intel(R) Xeon(R) Platinum 8369B 2.70GHz CPU, 256 GB RAM, and 1TB ESSD PL1 disk (350MBps and 50K IOPS). All nodes are connected via 32Gb Ethernet. The Result are shown on following figures.
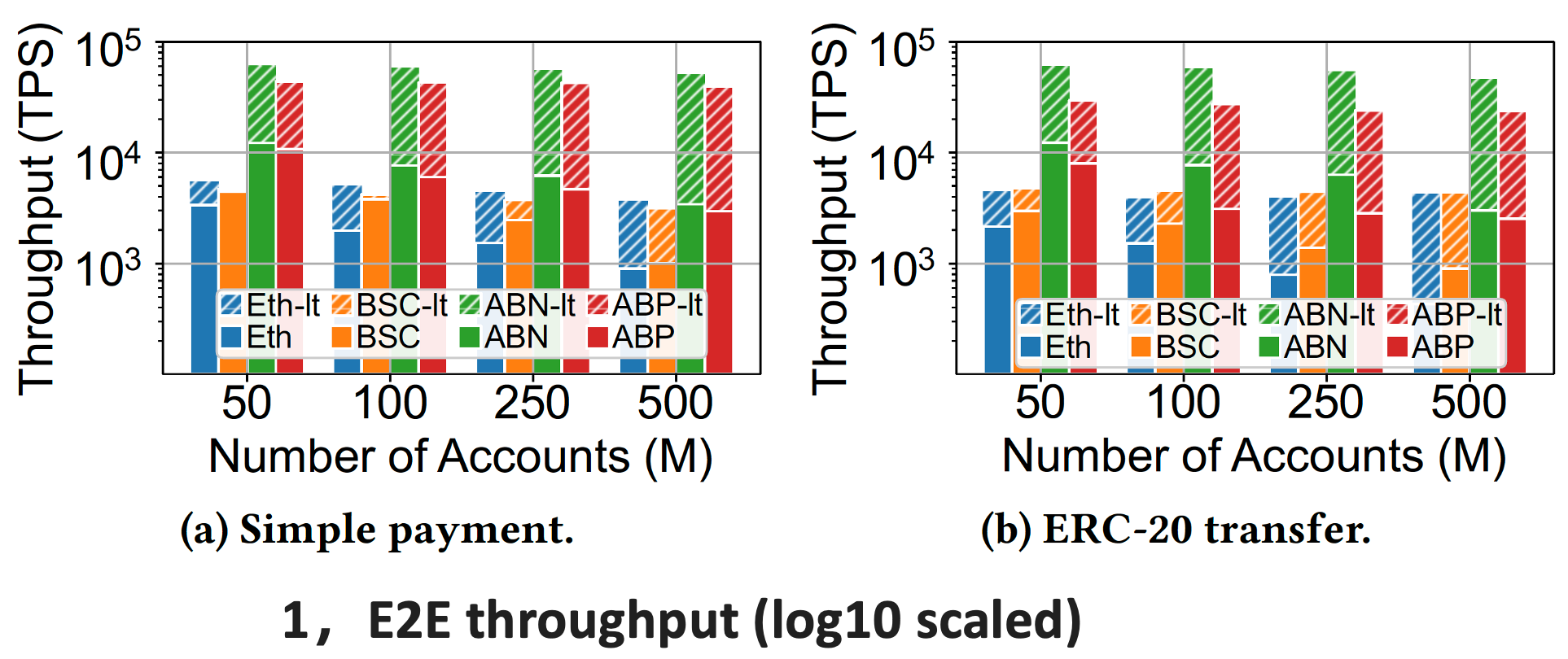
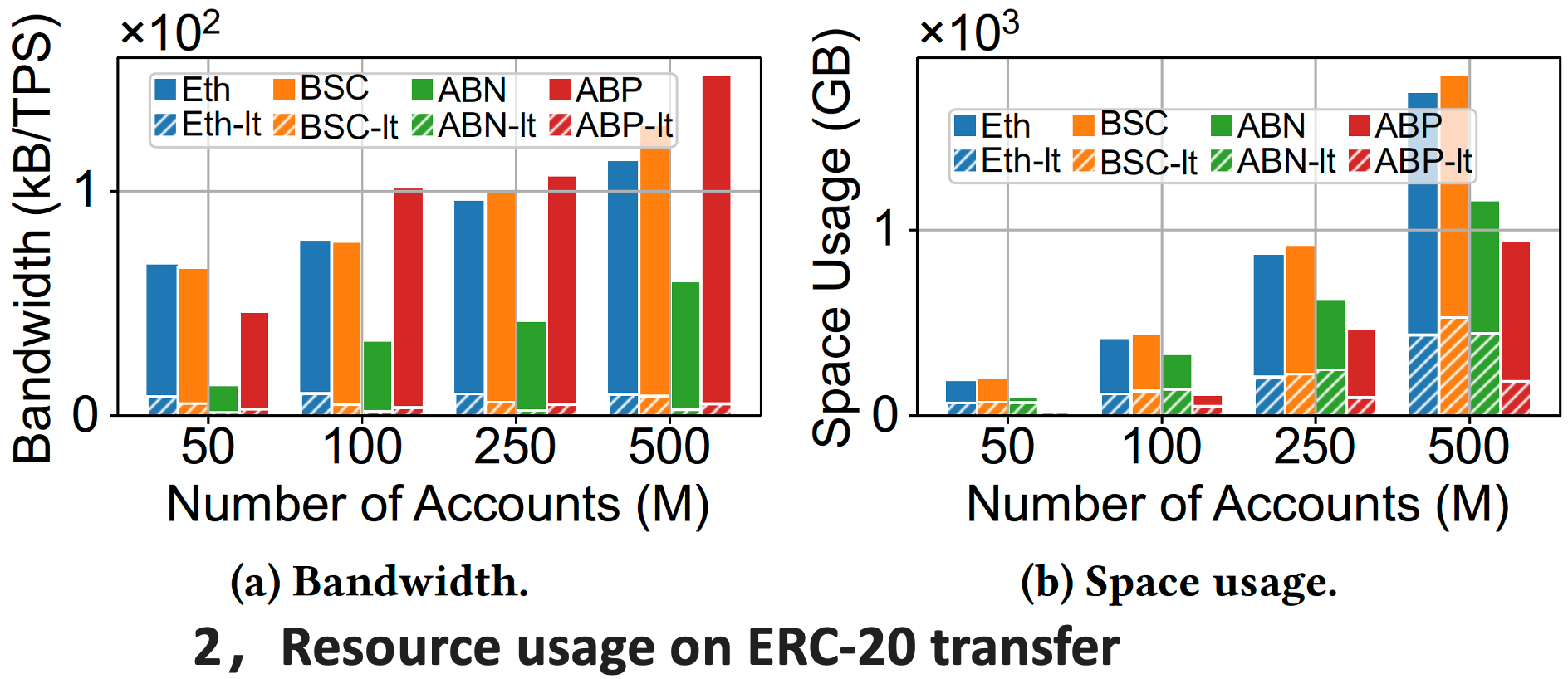
For the simple payment workload, LETUS significantly improves the end-to-end throughput by up to 14.8 times. For the ERC-20 transfer workload, LETUS improves the throughput by up to 15.8 times. To show the resource efficiency, we evaluate the disk bandwidth and space usage under different account numbers on ERC-20 transfer workload. It shows that LETUS reduces the space usage by up to 80.3% and reduces disk bandwidth usage by up to 95%. The significant enhancement comes from the delta-encoding and version-based indexing schema, which reduces I/O and space consumption.
Metrics from Production Environment
During the 2023 Asian Games in Hangzhou, AntChain with LETUS successfully supported the digital flame ignition event, where over 100 million torchbearers from more than 100 countries lit the digital torches in real-time online. Let's show some detailed metrics from the real-world production environment.
As of March 2024, the total count of key-value pairs of TopNod is about 200 million. During a flash sale event, the average TXN processing time of the network was 78 ms, while the time in storage was only 14.8 ms (account for only 18.8%). A double write mode of LETUS and an optimized MPT (MPT-opt) had been deployed in TopNod, and global state was submitted to both of them at the same time. Disk usage metrics were collected at two different time points. At the first time point, mpt-opt consumed 191.9GB, while LETUS consumed 105.2GB (45.2% saving). At the second time point, mpt-opt consumed 265.2GB, while LETUS consumed 121.5GB (54.2% saving). The metrics collected from the production environment show that LETUS has high performance and low resource consumption.
Conclusion and Future Work
LETUS introduce a new architecture with delta-encoding and version-based indexing schema, as well as block tiering and state pruning proposed. It is an universal storage that provides high performance, large scale, low cost, and universal for different blockchains.
However there are also some limitations, such as range query and page loading. Some works are in progress, such as complex query, MPT fully compatible, and fast-sync. In the future, we will also develop zero-knowledge friendly ADS and blockchain layer 2 storage.
[1] Chenxing Li, Sidi Mohamed Beillahi, Guang Yang, Ming Wu, Wei Xu, and Fan Long. 2023. LVMT: An Efficient Authenticated Storage for Blockchain. In 17th USENIX Symposium on Operating Systems Design and Implementation. 135–153.
[2] Soujanya Ponnapalli, Aashaka Shah, Souvik Banerjee, Dahlia Malkhi, Amy Tai, Vijay Chidambaram, and Michael Wei. 2021. RainBlock: Faster Transaction Processing in Public Blockchains. In 2021 USENIX Annual Technical Conference. 333–347.
[3] Hyperledger. 2019. https://www.hyperledger.org/.
[4] Z Amsden et al. 2020. The Libra Blockchain. https://diem-developerscomponents.netlify.app/papers/the-diem-blockchain/2020-05-26.pdf.
[5] Sheng Wang, Tien Tuan Anh Dinh, Qian Lin, Zhongle Xie, Meihui Zhang, Qingchao Cai, Gang Chen, Wanzeng Fu, Beng Chin Ooi, and Pingcheng Ruan. 2018. Forkbase: An efficient storage engine for blockchain and forkable applications. Proceedings of the VLDB Endowment 11, 10 (2018), 1137–1150.
About ZAN
As a technology brand of Ant Digital Technologies for Web3 products and services, ZAN provides rich and reliable services for business innovations and a development platform for Web3 endeavors.
The ZAN product family includes ZAN Node Service, ZAN ZK Acceleration, ZAN Smart Contract Audit (AI Scan/Expert Audit), with more products in the pipeline.